
1. 트렌드의 변화 : 시장은 지금 어떻게 변화하고 있나?
2. 대용량 데이타의 고속 전송 : HBM 메모리는 어떻게 동작하나?
3. 리눅스에서 HBM 메모리로 Tiering 하는 방법 : Hot data 배열하기
4. HBM 포화 시 자동 완화 정책 설계 : ‘Memory Pressure’ 대응하기
1. 트렌트의 변화
-
2026.02.07 : Brendan Gregg가 인텔을 떠나서 OpenAI로 합류 했다 !AI 데이터센터 성능 문제를 기술적 챌린지를 넘어 환경·비용·사회 문제로 확장된 도전으로 인식했고, 이를 직접 해결하기 위해 OpenAI에 합류했다는 철학적·전문적 이유를 그의 블로그를 통해서 확인이 가능하다.이제 인공지능 시대로 넘어가면서 고성능 데이타 센터에 대한 성능과 비용 그리고 기반 인프라에 요구되는 시설까지 (전원, 쿨링) 이제는 현실화로 이어져야 할 시기가 다가온듯 하다. 참고:Brendan Gregg :Why I joined OpenAI
-
2026.02.11 :DDR 메모리 가격이 레디컬하게 증가하기 시작했다 삼성이나 하이닉스와 같은 메모리 제조사들은 AI 데이타 센터의 확장으로 HBM 메모리 생산으로 집중하기 시작하면서 최근의 메모리 가격 상승은 단순한 공급망 쇼크라기보다, AI 인프라 확대와 산업 구조 변화가 겹친 구조적 부족 상황이라는 평가가 지배적이다 개인적인 관점이기는 하지만 이제 리소스 관점에서의 엔지니어링 기법이 다시 필요한 시점이 될듯하다. 유닉스에서 리눅스로 전환될때 어플리케이션의 프레임 워크는 Posix 표준에 맞춰져서 개발해야 하고 리소스에 대한 활용에 대한 관점을 바꿔야 했다. 작게는 리눅스지만 좀더 크게는 시스템 성능 엔지니어링 관점의 리소스 활용에 대한 전략이 무엇보다 필요한 시대가 되어간다.
참고자료 : 2024–present global memory supply shortage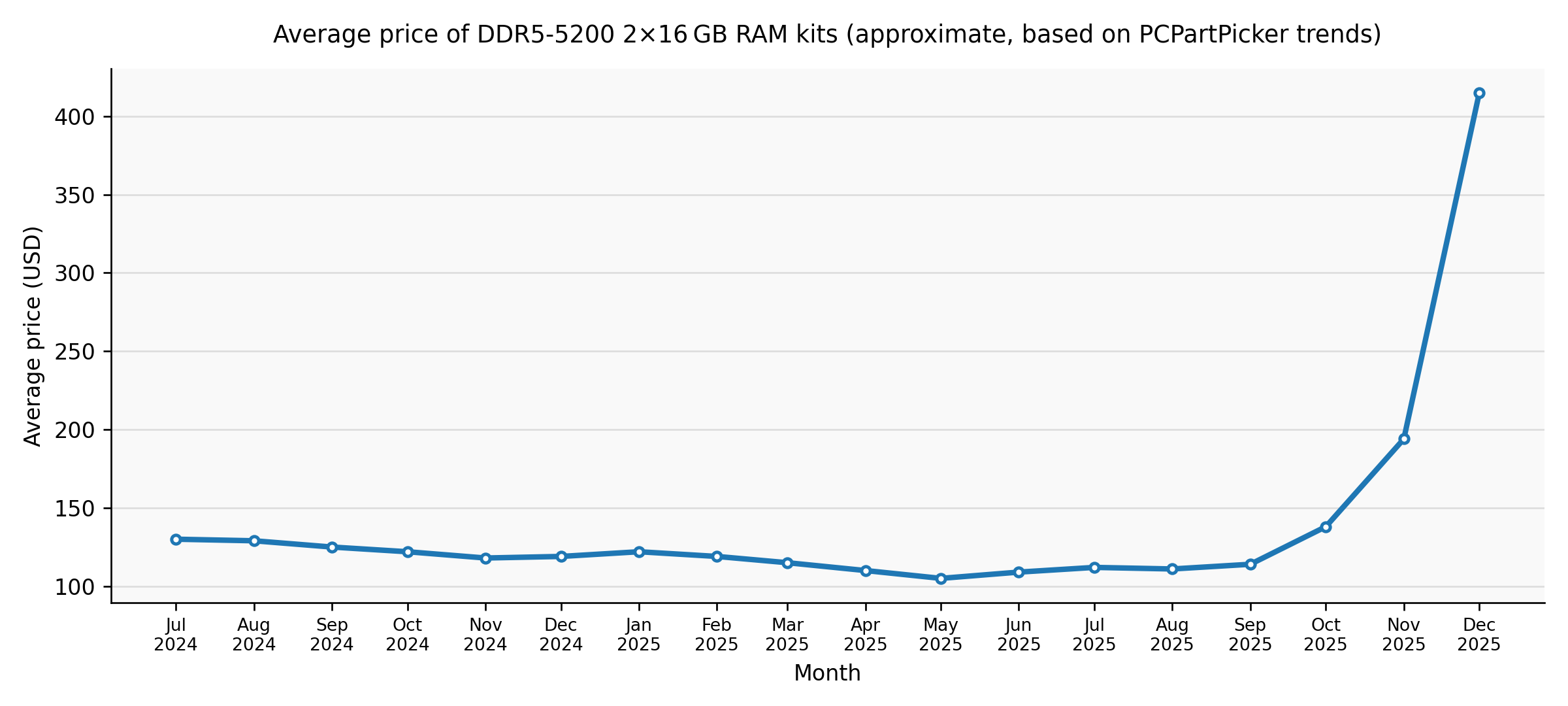
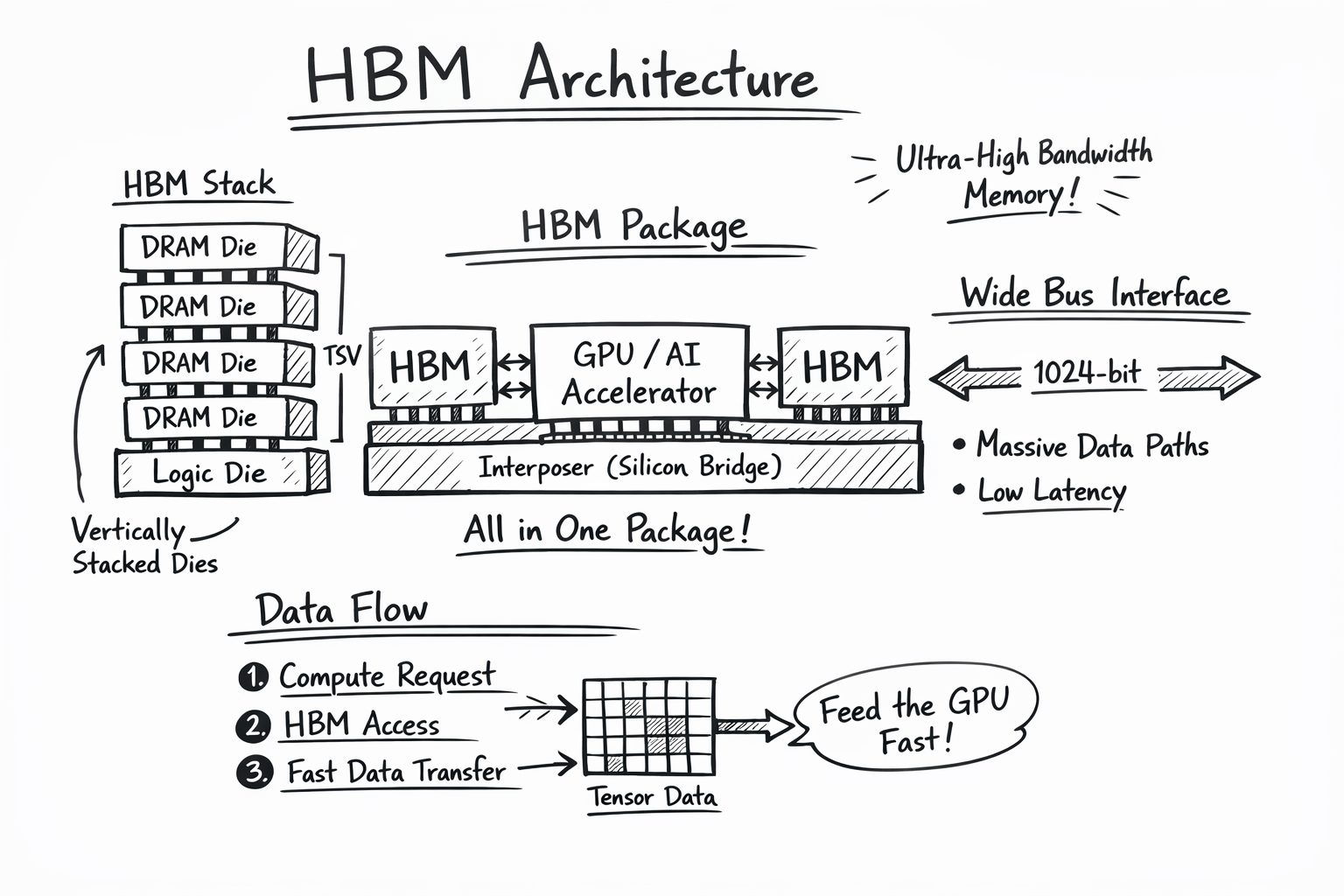
2. HBM 메모리는 어떻게 동작하나?
- 2026.02.16 : HBM은 “연산 유닛(GPU/AI Accelerator)이 굶지 않도록 초고속으로 데이터를 공급하는 메모리”
- HBM은 메모리의 클럭 보다는 고대역폭을(1024bit) (낮은 클럭 + 매우 넓은 버스 = 고대역폭 + 낮은 전력) 으로 데이타를 GPU에 공급
- HBM은 Cache의 역할이 아니며 연산 전용 고속 주 메모리
- 실제 동작 흐름 (AI 워크로드 기준) Transformer 모델 추론 –> GPU 코어(SM)가 연산 요청 –> 메모리 컨트롤러가 HBM에 병렬 요청 –> 수천 비트 폭으로 텐서 데이터 전달 –> 연산 유닛은 대기 없이 연산 지속
- OS/런타임은 어떤 데이터를 HBM에 둘 것인가? 를 결정하는 쪽으로 진화 중
- 리눅스 NUMA와 메모리 tiering에서 HBM은 가장 빠른 NUMA 노드로 hot data를 끌어올리는 성능 가속 레이어로 사용된다.
3. 리눅스에서 가장 빠른 HBM 노드로 티어링
- 티어링의 목표 : 리눅스에서 HBM 메모리의 티어링의 정책은 자주 접근되는 페이지 (hot page)를 자동 또는 정책적으로 HBM으로 올린다.
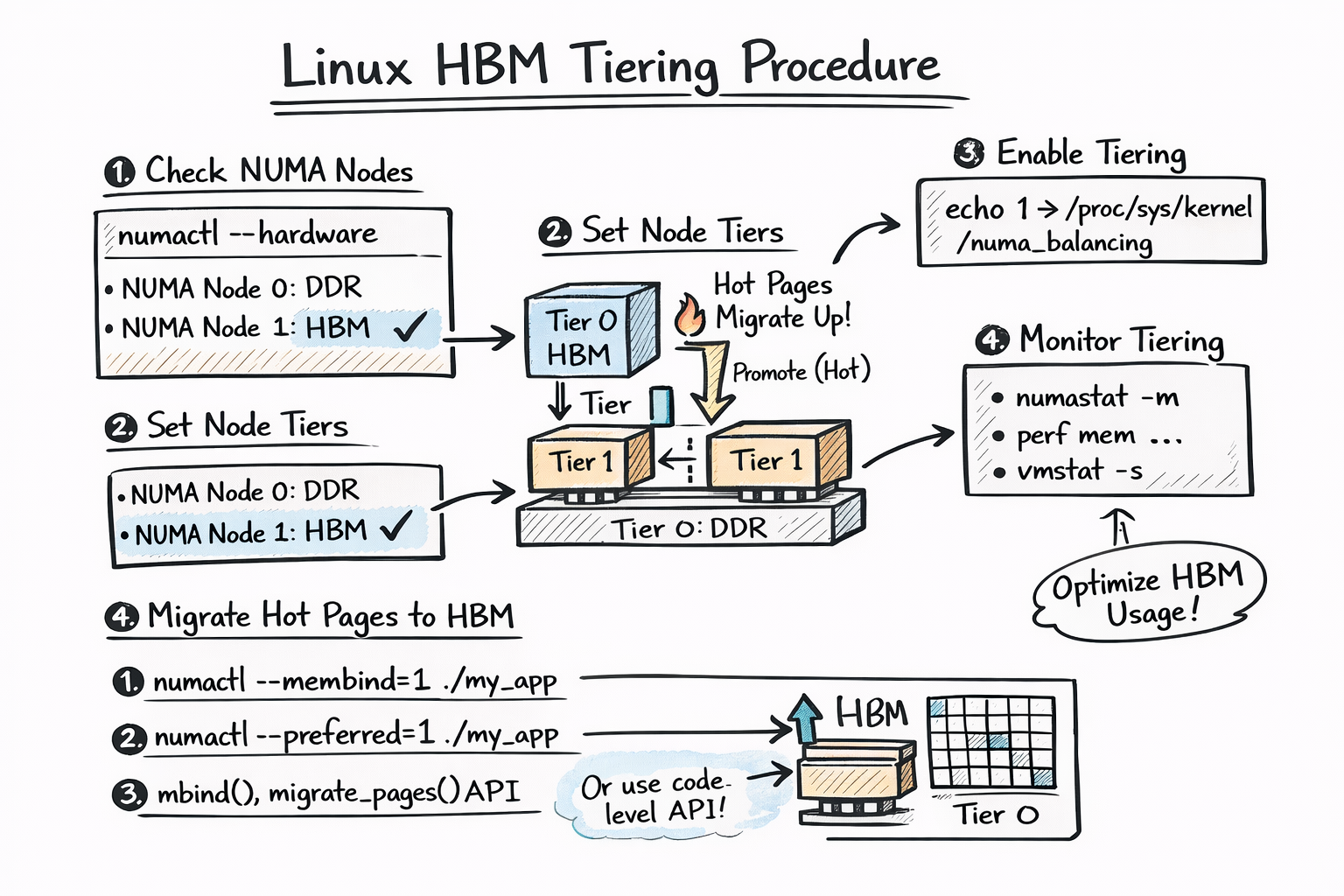
- 리눅스는 노드의 성능 특성(distance + bandwidth)로 tier로 구성하게 된다. (커널이 어느 노드가 빠른지 알게 하기)
- 각 노드는 자기에게 맵핑된 메모리를 사용하는 것이 가장 빠르게 접근할수 있는 방법
- 다른 노드의 접근은 메모리 접근 성능에 있어서 페널티가 발생할수 밖에 없다.
- ex) node 0 (DDR) / node 1(HBM) 메모리의 이상적인 티어링 환경
numactl --hardware (check Node Topology)
node 0 size: 512 GB (DDR)
node 1 size: 64 GB (HBM)
numactl --distance
node 0 1
0 10 30
1 30 10 ← (Distance High, bandwidth loW = Tier 0)
cat /proc/sys/kernel/numa_balancing (Enable numa balancing for auto Tiering)
1 ← enable
- CPU 1번 노드에서 프로세스를 실행하고, 메모리 할당을 1번 노드(HBM으로 가정)로 강제함.
- 리스크: 만약 1번 노드의 HBM 용량이 부족할 경우, 프로그램은 DDR 메모리를 빌려 쓰지 못하고 OOM(Out Of Memory) 에러 를 내며 종료됨
numactl --membind=1 --cpunodebind=1 ./app
- HBM의 대역폭을 최대한 활용하되, 용량 부족으로 인한 강제 종료를 막으려면 –membind 대신 –preferred 사용을 권장
- 1번 노드(HBM)를 우선 사용하되, 부족하면 다른 노드(DDR) 사용
numactl --cpunodebind=1 --preferred=1 ./app
- 단순 실행이 목적이라면: numactl 사용은 정석적인 방법 중 하나지만. 다만, numastat 명령어를 통해 실행 중 실제로 메모리가 1번 노드에 쌓이는지 모니터링이 필요함
- 안정성이 중요하다면: –membind 대신 –preferred를 고려하세요.
- 성능 최적화가 목적이라면: 소스 코드에서 Memkind 라이브러리 를 적용하는 방향을 추천합니다
Memkind는 메모리 종류를 Kind라는 객체로 관리
MEMKIND_DEFAULT:일반적인 시스템 메모리 (DDR)MEMKIND_HBW:고대역폭 메모리 (HBM)MEMKIND_HBW_PREFERRED:HBM을 우선 시도하되, 없으면 DDR 사용
#include <memkind.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
struct memkind *hbm_kind = MEMKIND_HBW;
double *data;
size_t size = 1024 * sizeof(double);
// 1. HBM 가용 여부 확인
if (memkind_check_available(hbm_kind) != 0) {
fprintf(stderr, "HBM을 사용할 수 없는 환경입니다.\n");
return 1;
}
// 2. HBM에 메모리 할당
int err = memkind_malloc(hbm_kind, size, (void **)&data);
if (err) {
fprintf(stderr, "HBM 할당 실패\n");
return 1;
}
// 데이터 사용
for (int i = 0; i < 1024; i++) {
data[i] = i * 1.5;
}
// 3. 할당 해제 (반드시 memkind_free 사용)
memkind_free(hbm_kind, data);
printf("HBM 작업 완료\n");
return 0;
}
- 마이그레이션 통계 확인
numactl --m
확인 포인트:
HBM hit 비율이 올라가면 성공
numa_hitnuma_missnuma_foreignnuma_interleave
4. HBM 포화 시 자동 완화 정책 설계
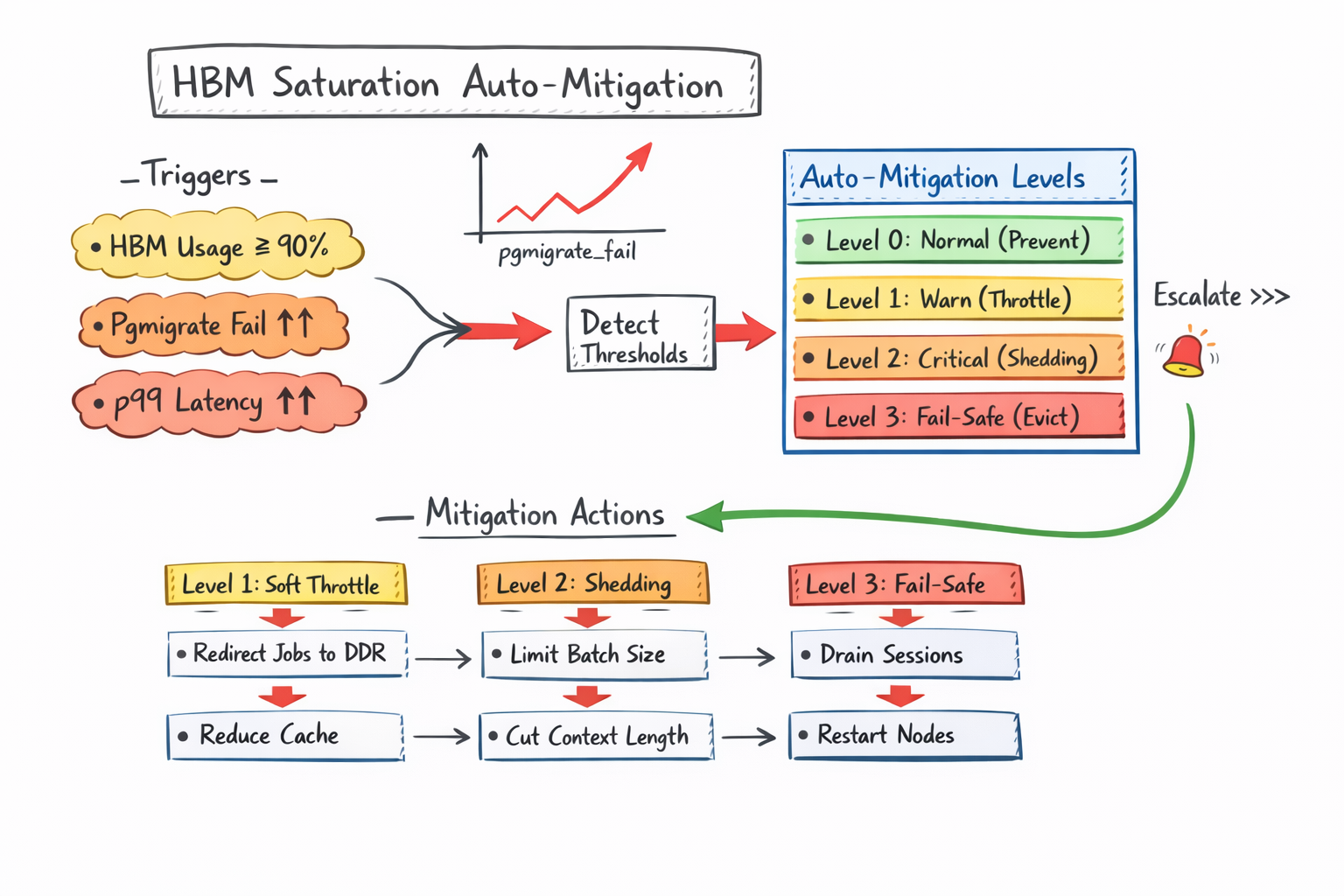
- 핵심은 단순히
메모리가 부족하면 프로세스를 죽인다(OOM Killer)는 식의 대응이 아니라,계층화된 대응(Level 0~3)과성능 지표(p99, Migration Fail)를 연동함으로써 HBM 메모리와 점유율과 관련된 관찰 가능성 (Observability)이 자동화 정책 핵심
1.HBM 포화가 위험한 이유: 연쇄 장애의 메커니즘
- HBM Free 급감: 새로운 핫 페이지(Hot Page)를 올릴 공간이 고갈됨.
- Page Migration 실패: DDR에 있는 데이터를 HBM으로 승격시키려는 시도가
실패(pgmigrate_fail 증가) - Remote Access 폭증: HBM에 들어가지 못한 데이터가 DDR에 머물며 CPU/GPU가 멀리 있는 데이터를 읽어오게 되고(
numa_miss), 결과적으로 p99 지연 시간이 폭증.
2.감지 신호(Trigger) 설계: “무엇을 볼 것인가?”
HBM 포화 상태를 정밀하게 감지하기 위해 관리자가 반드시 추적해야 할 4가지 핵심 지표군입니다.
| 구분 | 지표명 | 임계치 (예시) | 의미 및 영향 |
|---|---|---|---|
| 용량 | MemFree / MemUsed |
WARN: 85% / CRIT: 92% | HBM의 물리적 여유 공간 및 고갈 여부 |
| 효율 | pgmigrate_fail |
1분간 지속 상승 시 | 계층 간(HBM↔DDR) 메모리 이동의 병목 현상 |
| 성능 | numa_miss / numa_hit |
Baseline 대비 Miss 급증 | 원격 메모리(DDR) 참조로 인한 처리 속도 저하 |
| 체감 | p99 Latency |
Baseline 대비 +30% 지속 | 실제 사용자가 느끼는 서비스 품질 및 응답 저하 |
3.자동 완화 정책의 4단계 (Level 0 ~ 3)
Level 0: 정상 (Prevent)
numactl --membind=<HBM_NODE>으로HBM을 우선 사용하되 부족하면 DDR로 자연스럽게 배치.• 주의: hard bind는 절대 금물.HBM은 용량이 작기 때문에 꽉 차는 순간 프로세스가 즉사(OOM).
• 핵심: CPU와 HBM 노드의 Affinity를 유지하며 백그라운드 작업은 처음부터 DDR에 배치.
Level 1: 경고 (Soft Throttle)
• 조치: 새로 시작되는 비핵심 작업(배치, 로그 압축, 인덱싱 등)을 강제로 DDR 노드에 배치.
• 예제: 실행 래퍼에서
numactl --membind=<DDR_node> 적용.• 격리: 해당 노드를 'Degraded'로 마킹하여 스케줄러가 새 워크로드를 배치하지 못하게.
• 목표: HBM의 추가 소모를 억제하여 핫셋(Hot-set) 공간을 보호합니다.
Level 2: 위험 (Workload Shedding)
• 조치: 서빙 트래픽을 경량 모드로 전환하여 메모리 점유를 줄여줌.
• LLM 기준: Max Context Length 제한, Batch Size 축소.
• Admission Control: 세션/테넌트별 HBM Quota를 적용해 특정 유저의 독점을 방지.
• 목표: 핵심 모델과 KV Cache를 보호하고 나머지를 희생하여 가용성을 유지.
Level 3: 임계 (Fail-safe)
• 조치: 서비스 안정성을 위해 강도 높은 물리적 제어를 실행.
• 드레인(Drain): 일부 모델이나 테넌트를 강제 축소하거나 요청을 차단.
• 격리: 해당 노드를 'Degraded'로 마킹하여 스케줄러가 새 워크로드를 배치하지 못하게 함.
• 재시작: 누적된 파편화(Fragmentation) 해결을 위해 프로세스 롤링 재배치를 수행.
4. 실무자를 위한 체크리스트
- 100%를 다 쓰려 하지 말고, 항상 10~15%의 여유를 두어야 핫 페이지가 들어올 문이 열립니다.
[ ] numastat -m을 통해 노드별 메모리 상태를 주기적으로 로깅하고 있는가?
[ ] 서비스의 p99 지연 시간과 메모리 Migration 실패율이 연동되어 알람이 오는가?
[ ] 비핵심 워크로드를 즉시 DDR로 격리할 수 있는 스크립트가 준비되었는가?
[ ] 애플리케이션 레벨(vLLM, TGI 등)에서 KV Cache 크기를 동적으로 조절할 수 있는가?